RESEARCH // MULTI-MODEL ORCHESTRATION
The best single model is not the best system.
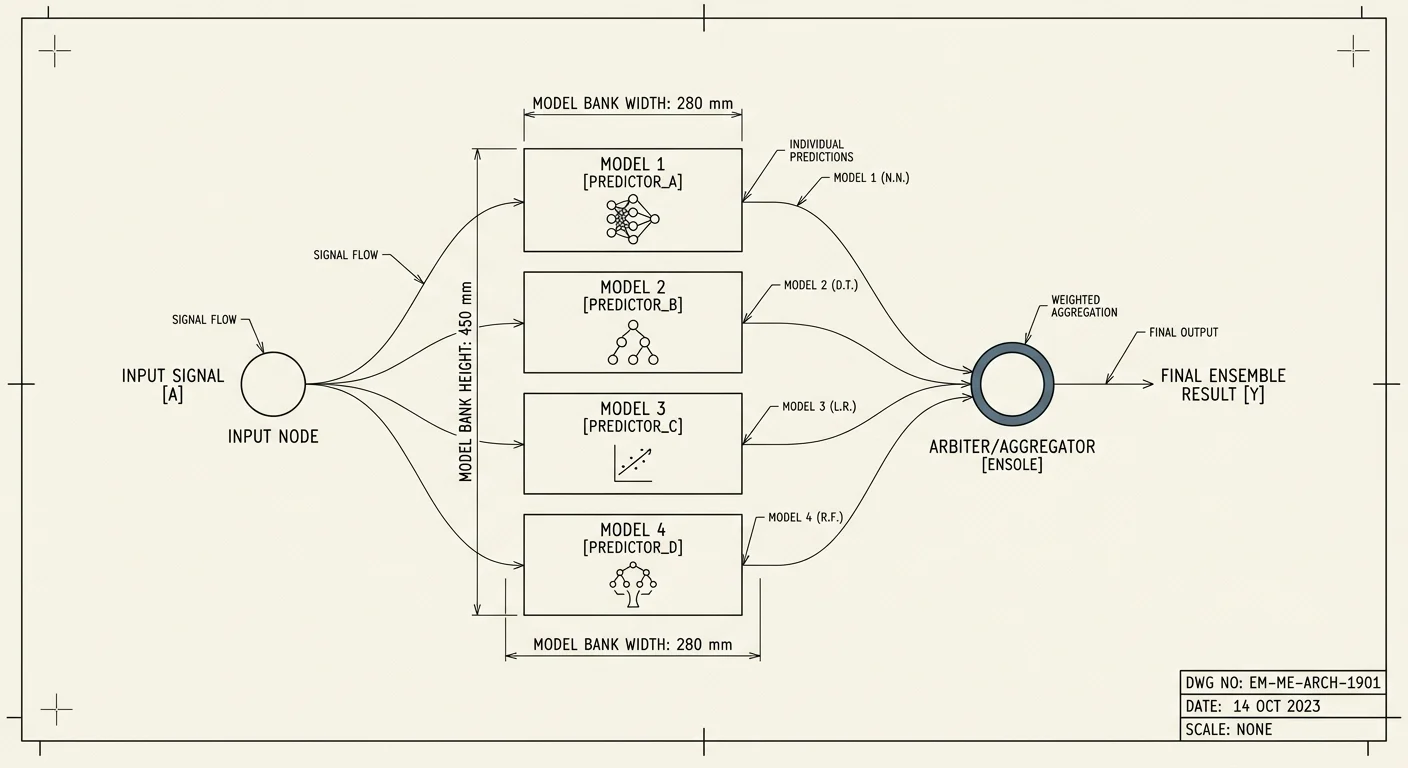
For most tasks, picking the strongest available model and routing everything through it is the right call, and we say so. But for high-stakes decision intelligence, where a wrong answer is expensive and confidence has to be earned, the single-model reflex leaves value on the table. A disagreement between two strong models is information you should not throw away.
This thread is about when orchestrating multiple frontier models beats using the best one alone, and how to combine them so the ensemble is genuinely more trustworthy rather than merely more expensive.
SPEC_ID: RESEARCH-MMO-01 // STATUS: ACTIVE // SHIPPED IN PRODUCTION RETRIEVAL
FIG. ENSEMBLE_OF_ESTIMATORS
REF: MMO-00