RESEARCH // SAFETY-CRITICAL DECISIONS
The model that talks should not be the model that decides.
Conversational AI is now genuinely good at the front of a clinical interaction. It listens to a person describe their symptoms, asks follow-ups, and sounds calm and human while doing it. That competence is seductive, and it invites a dangerous design: let the conversational model also make the triage call.
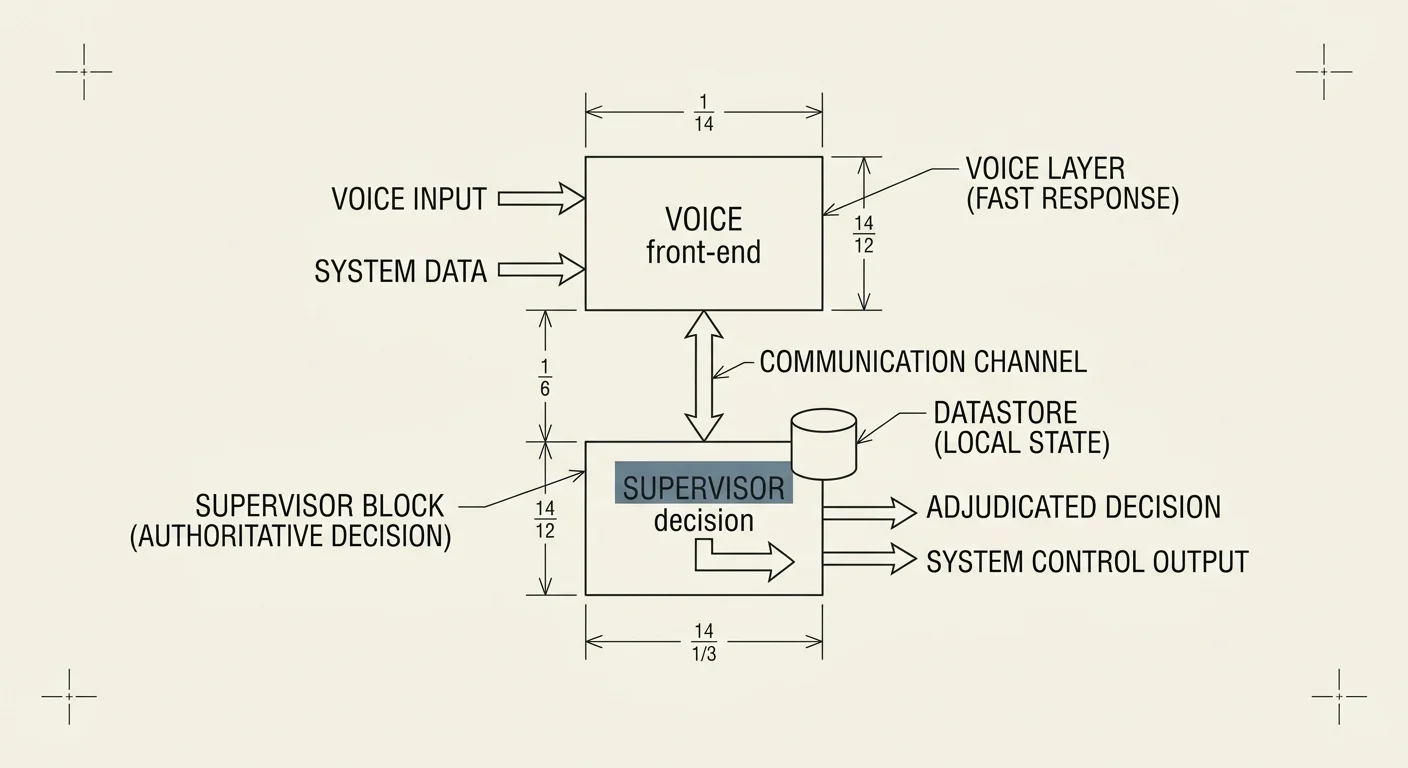
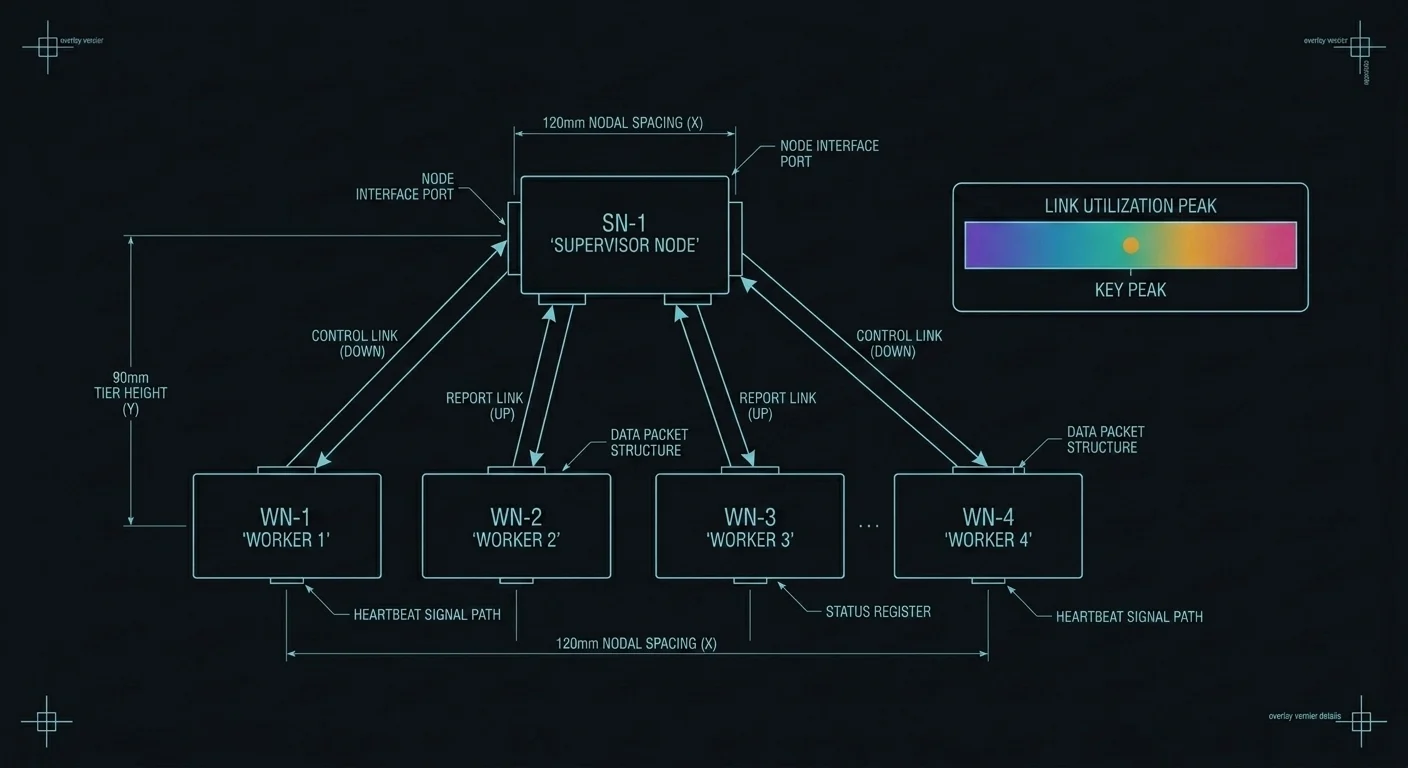
We do not believe that is safe. This thread is about an architectural answer, separating the conversation from the decision, and about the auditability you buy by refusing to put both in the same model.
SPEC_ID: TRIAGE-ARCH // STATUS: ACTIVE THREAD // DOMAIN: HEALTHCARE → GENERAL
FIG. SUPERVISOR / FRONTEND SPLIT
REF: TRIAGE-00