RESEARCH // GENERATIVE SEARCH OPTIMIZATION
Does the model name your brand, and can you prove why?
The post-search era is not coming. It is here. When a user asks an assistant a question, there is no results page to rank on. There is a synthesized answer, and either your brand is named inside it or it is not.
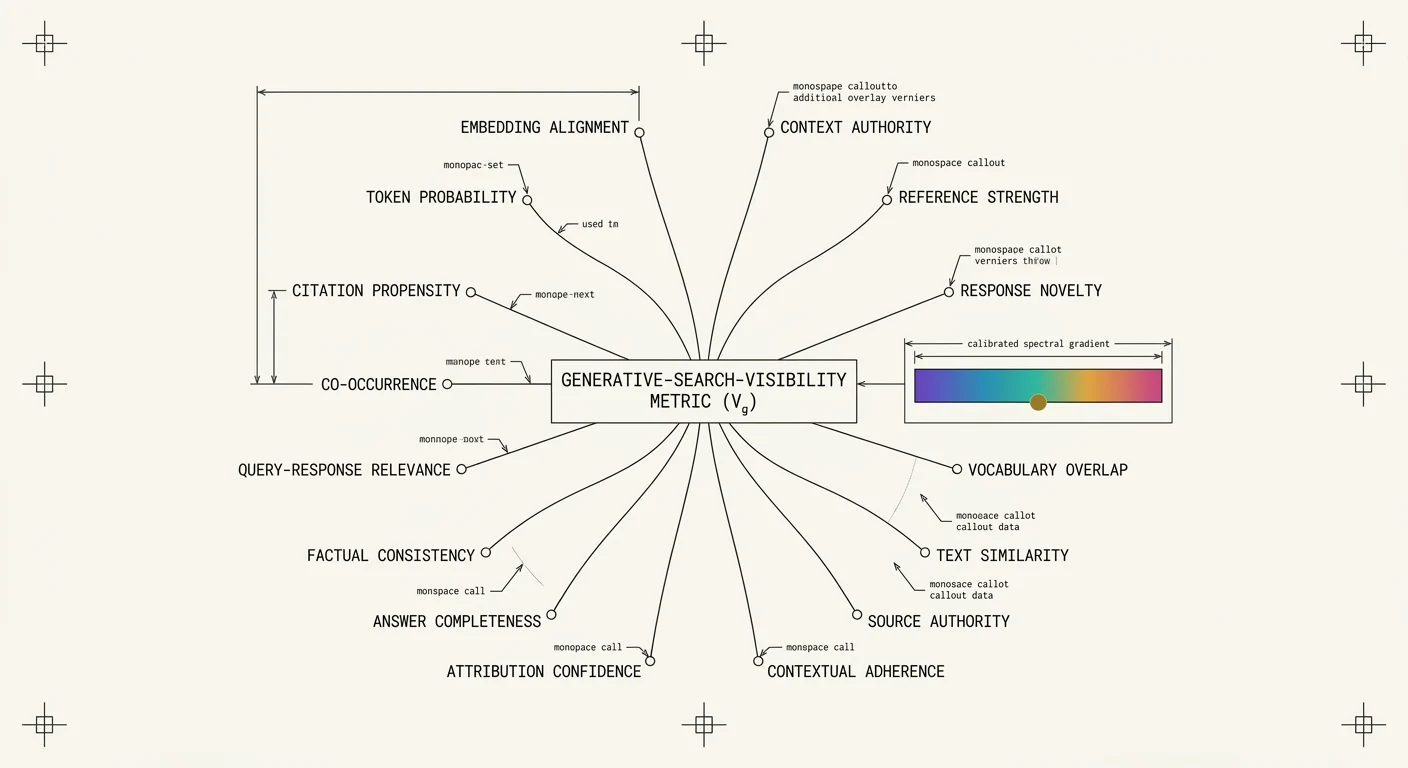
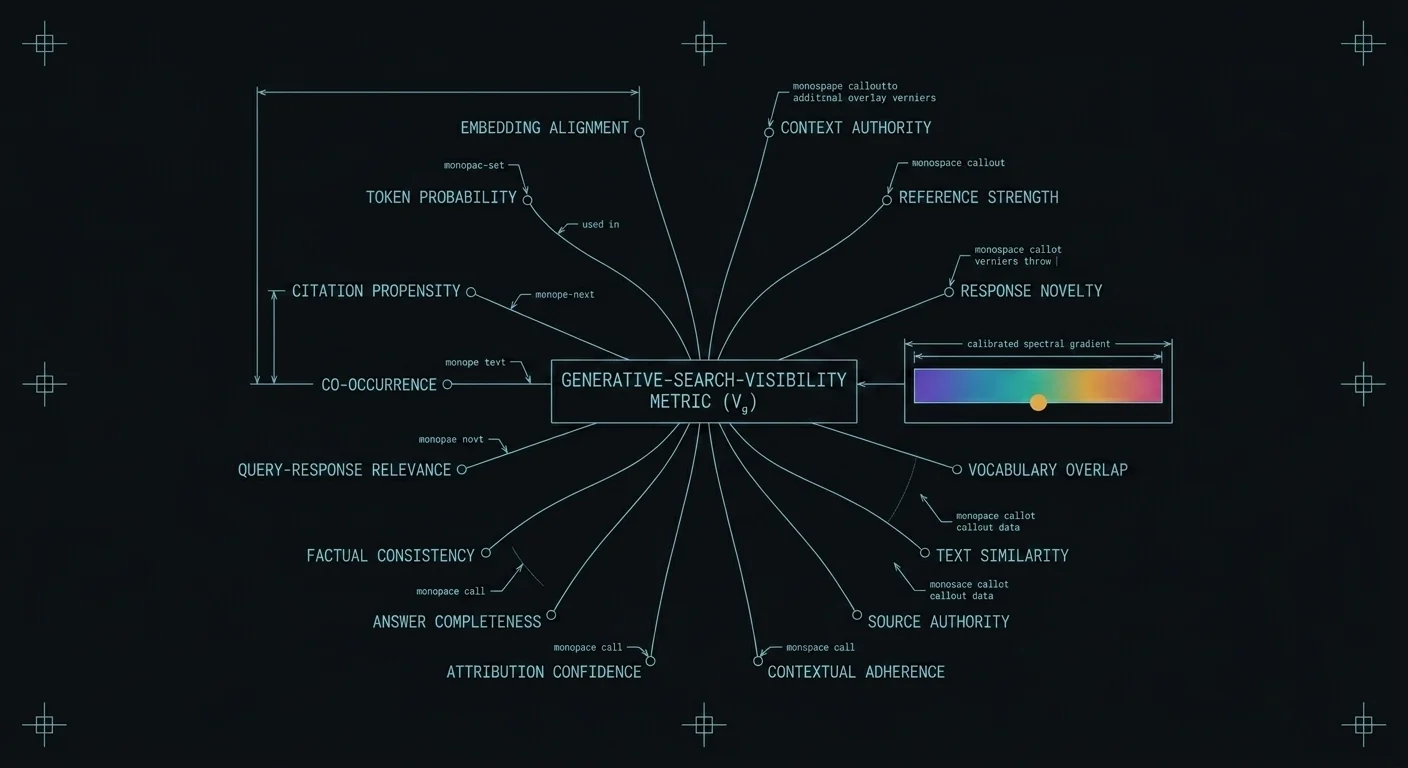
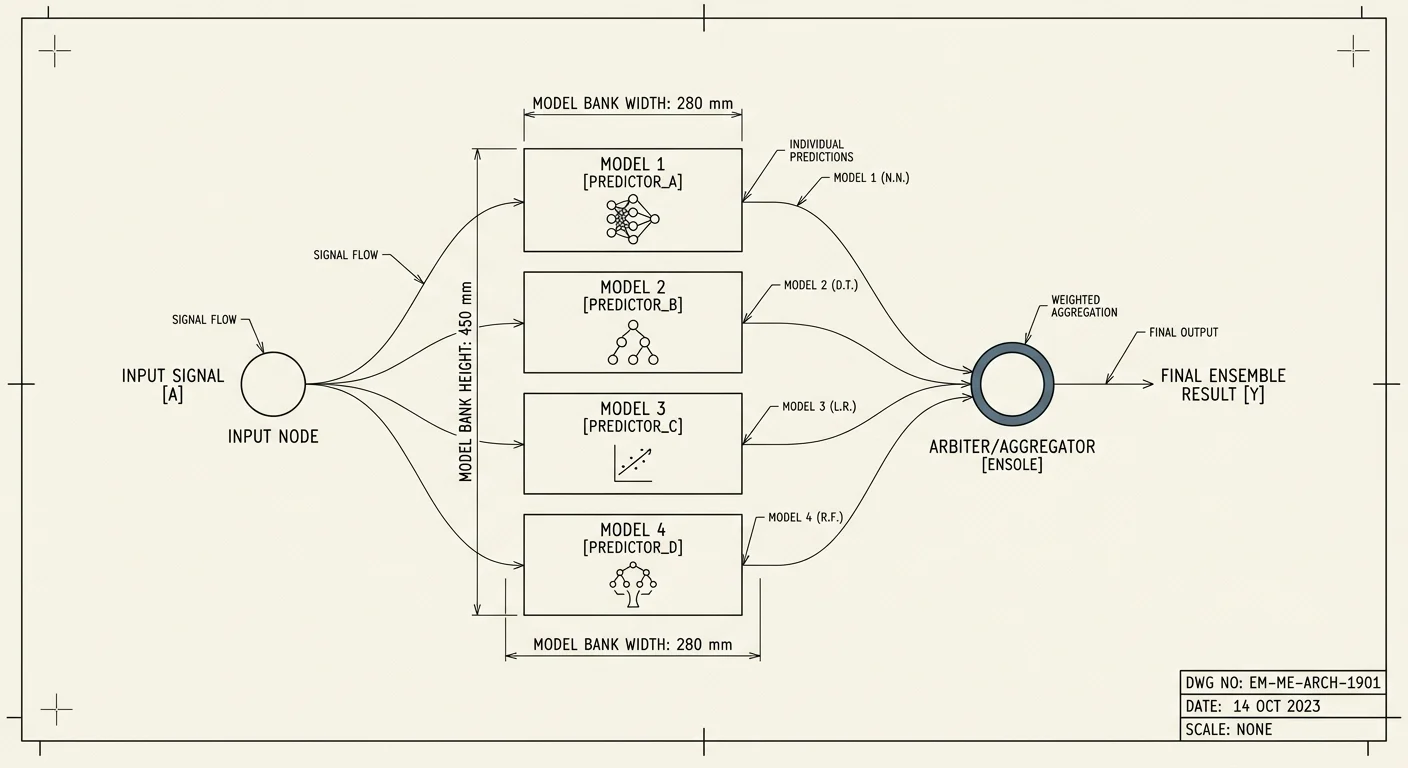
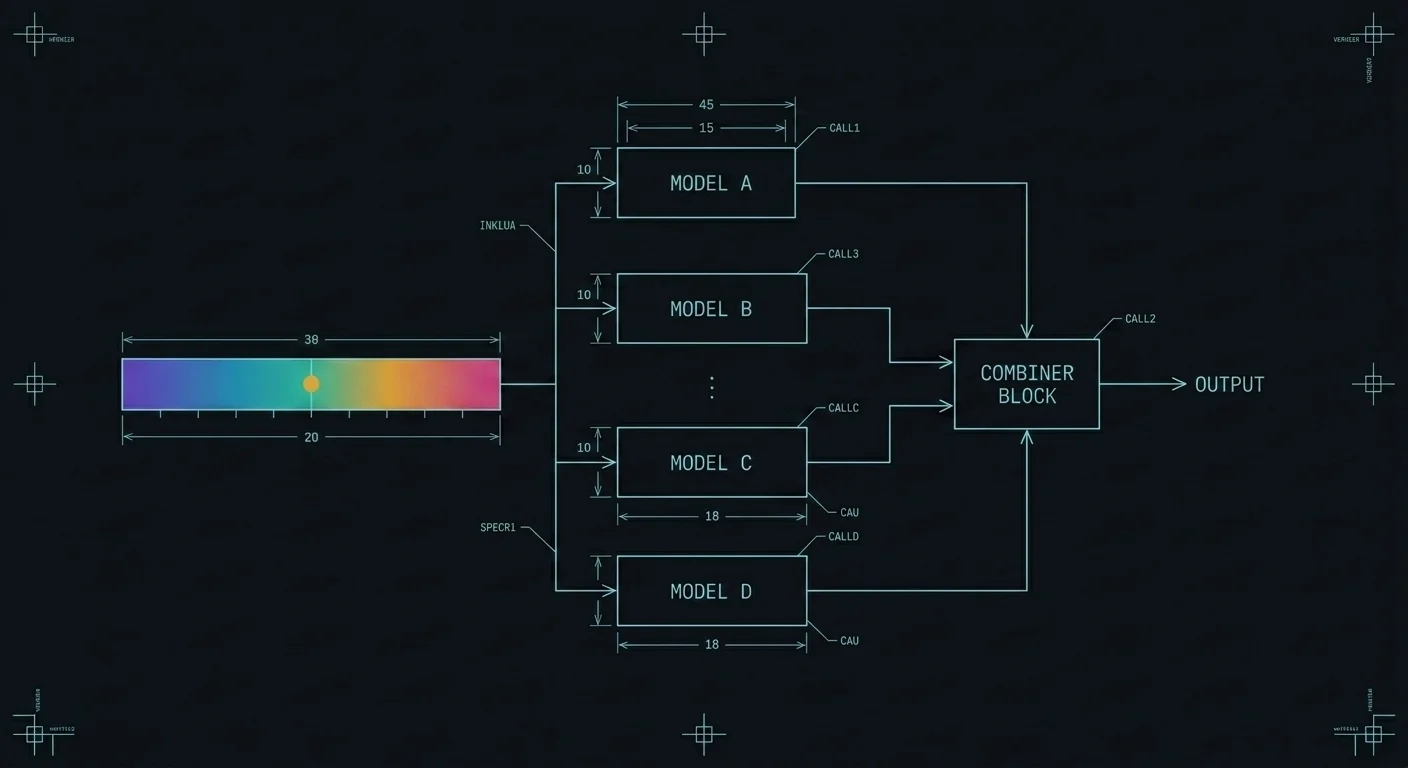
This thread is about turning that into something measurable. We call the discipline Generative Search Optimization, and the working thesis is that visibility inside a generated answer is not a coin flip. It is decomposable, instrumentable, and ultimately tunable: know which knob to turn.
SPEC_ID: GSO-RESEARCH // ~14-METRIC FRAMEWORK // MODEL-AGNOSTIC
FIG. VISIBILITY_DECOMPOSITION
REF: GEO-00