00 // PRODUCT // VOICE & COACHING
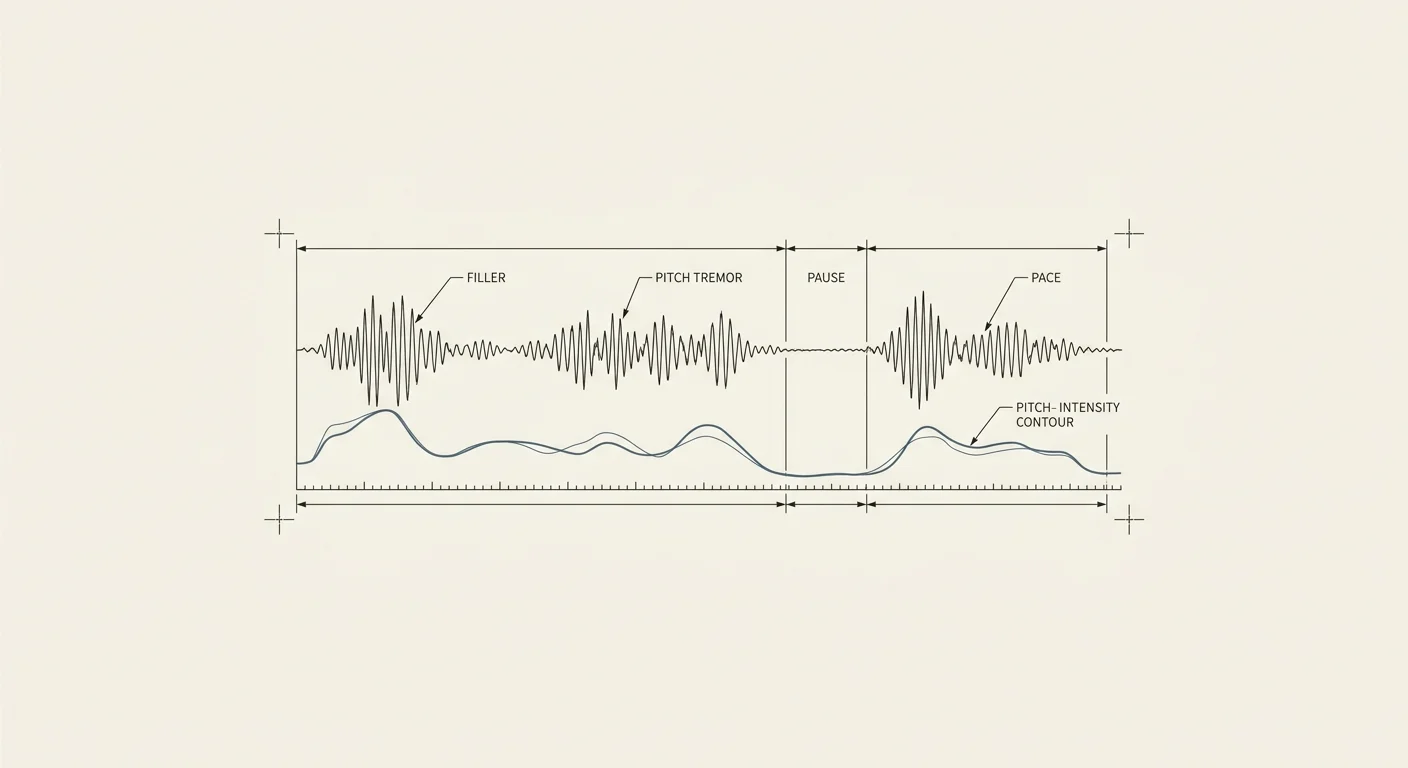
Practice speaking against the signal, not the transcript.
VoiceReady is a speaking-practice product that listens to how you actually sound (the ums and likes, the tremor under pressure, talking too fast, the hedging qualifiers that quietly undercut a point) and returns vocal-level feedback you can act on.
Most speaking coaches read your words. VoiceReady measures your delivery. The difference is the whole product.
ACOUSTIC ANALYSISSOLO / LIVE-CALL / COACHINGTEAM-READY
FIG. SIGNAL_NOT_TRANSCRIPT
REF: VOICEREADY-00